



みなさんこんにちは! 現在、東京大学工学部に在籍している、さとうじょうゆです!
この記事では「ライバルよりも効率的にES対策を行う方法」をわかりやすく解説します

今回は、上記のポイントを押さえながらライバルよりも効率的にES対策をする方法を教えるぞ!
具体的には、「ES情報を整理してcsv形式に保存する作業を自動化」していきます
詳しいことは、この先を読んでください!Python使います!
※この記事を読んでわからないことがあればお気軽にお問い合わせください
この記事で紹介した方法でES対策をすれば、ライバルから差がつけられること間違いなし!
それでは行ってみよう!
ONE CAREERという就活情報サイト
今回、ES対策をするにあたって、ワンキャリアという就活情報サイトを参考にしていきます!
このサイトは、企業ごとの就活情報が詳細にまとまっているため、就活対策としてはとても有用です
このサイトから、先輩方のES情報を整理してcsvに保存するコードをPythonを使ってここからは書いていきます
コピペで大丈夫!
とりあえずここら辺はインポートしておいてください
import requests
from bs4 import BeautifulSoup
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import os
import time
from tqdm import tqdm【STEP1】One Careerのウェブサイトに自動的にログイン

WebDriverの初期化 (Chromeを使用)
webdriver.Chrome() を使って、Google Chromeブラウザの自動操作用に browser オブジェクトを初期化しています
Chrome WebDriverがシステムにインストールされており、実行可能なパスに設定されていることが必要です
browser = webdriver.Chrome()One Careerのログインページにアクセス
browser.get(url) を使用して、指定された url(One Careerのログインページ)にブラウザでアクセスします
url = "https://www.onecareer.jp/users/sign_in?store_return_to=https%3A%2F%2Fwww.onecareer.jp%2F"
browser.get(url)ユーザーからの入力受付
ユーザーにメールアドレスとパスワードを入力してもらいます
mail_address = input("メールアドレスを入力:")
password = input("パスワードを入力:")メールアドレスとパスワードの入力フィールドを見つけて、値を入力
browser.find_element(By.ID, “user_email”) と browser.find_element(By.ID, “user_password”) を使用して、メールアドレスとパスワードの入力フィールド(HTML要素)を見つけます
見つけた入力フィールドに対して、send_keys() メソッドを使用して、ユーザーが入力したメールアドレスとパスワードをそれぞれのフィールドに入力します
mail_address_box = browser.find_element(By.ID, "user_email")
mail_address_box.send_keys(mail_address)
password_box = browser.find_element(By.ID, "user_password")
password_box.send_keys(password)ログインボタンを見つけてクリック
browser.find_element(By.CSS_SELECTOR, “#new_user > input.v2-vform-submit”) を使用して、ログインボタンを見つけます
ここでは、CSSセレクタを使ってログインボタンに対応するHTML要素を指定しています
click() メソッドを使用してログインボタンをクリックし、ログイン処理を実行します
login_button = browser.find_element(By.CSS_SELECTOR, "#new_user > input.v2-vform-submit")
login_button.click()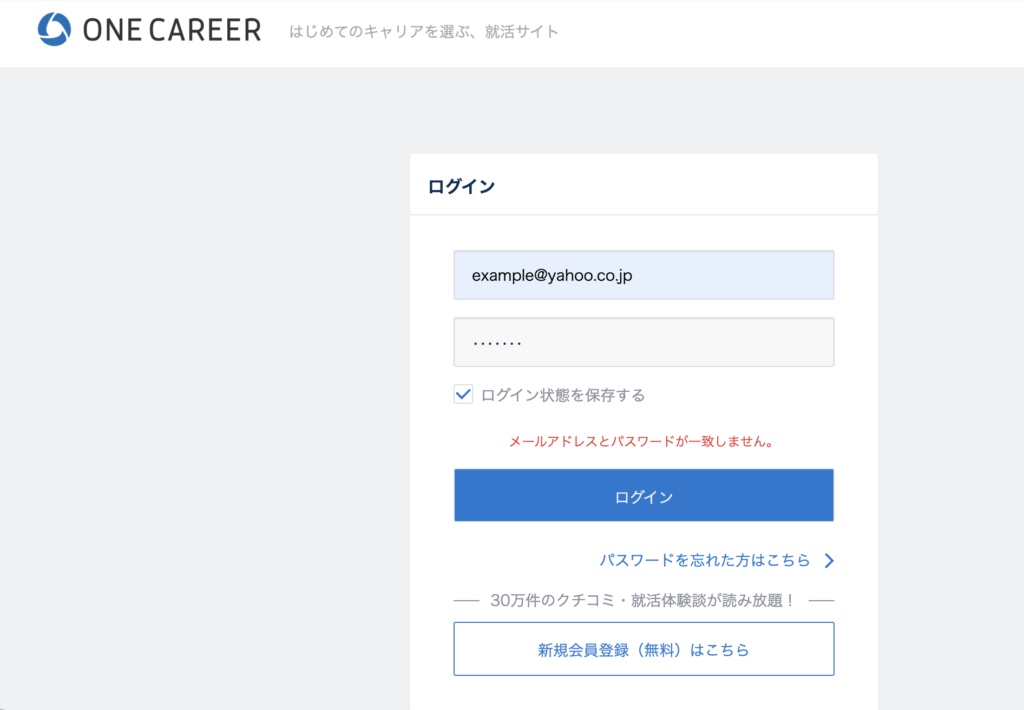
ここまでのコードを実行すると、ワンキャリアのサイトに自動でログインすることができます!
【STEP2】特定の会社に関連するESのURLを収集する

ユーザー入力の受付
ユーザーに会社名を入力してもらい、その値を company_name 変数に格納します
company_name = input("会社名を入力:")urlの収集のための準備
収集されるURLを格納するための空のリスト url_list を初期化します
url_list = []URL収集のメインループ
tqdm(range(1, 5)) を使用して、進行状況を視覚的に表示しながら、1ページから4ページまでの各ページに対してループを実行します
各イテレーションで、company_name とページ番号 i を使ってアクセスするURLを構築し、browser.get(url) でそのページにアクセスします
time.sleep(3) は、ページのロード完了を待つための暫定的な解決策です
ただし、この方法は効率が悪く、ページのロード時間に依存します
browser.find_elements(By.CLASS_NAME, “v2-experiences__item”) で、エントリーシートの各項目を表すHTML要素を全て取得します
それぞれの要素 (elem) に対して、find_element(By.TAG_NAME, ‘a’) でリンクを表す <a> タグを見つけ、get_attribute(“href”) でそのリンクのURLを取得します
取得したURLを url_list に追加し、コンソールに出力します
for i in tqdm(range(1, 5)):
url = "https://www.onecareer.jp/experiences?company={}&middle_categories%5B%5D=entry_sheet&order=latest&page={}".format(company_name, i) # 'https'のスペルミスを修正
browser.get(url)
time.sleep(3)
elems = browser.find_elements(By.CLASS_NAME, "v2-experiences__item")
for elem in elems:
url = elem.find_element(By.TAG_NAME, 'a').get_attribute("href")
print(url)
url_list.append(url)URLリストの重複削除と長さの表示
list(set(url_list)) を使用して url_list 内の重複を削除し、再びリストに変換します
最後に、リストの長さ(ユニークなURLの数)を出力します
url_list = list(set(url_list)) # 集合をlistに変換する
print(len(url_list))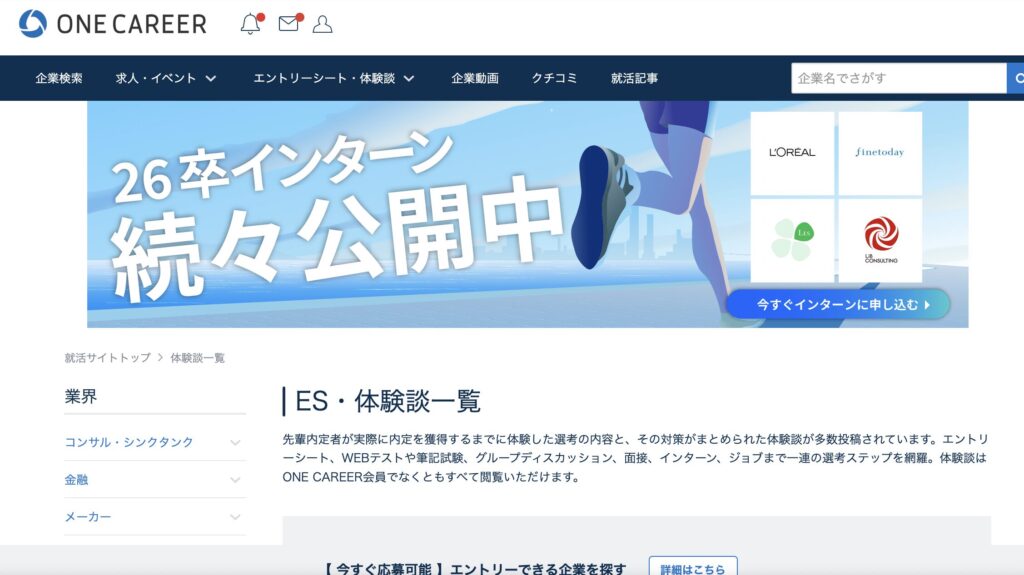
ここまでのコードを実行すると、調べたい会社のESページに自動的に遷移します!
【STEP3】URLリストの各ESページから情報を抽出する

リストの初期化
これらの行は、質問(question_list)、回答(answer_list)、寄稿者(contribute_list)情報を保存するための空のリストを初期化します
question_list = []
answer_list = []
contribute_list = []各ESを抽出する
for url in tqdm(url_list): は、進行状況を視覚的に表示しながら、url_list 内の各URLに対してループを実行します
browser.get(url) で指定されたURLにアクセスし、time.sleep(3) でページが完全にロードされるのを待ちます
browser.find_element(By.CLASS_NAME, “v2-curriculum-item-body__content”).text で、質問と回答が含まれる要素のテキストを取得し、elem = elem.split(“\n”) で改行ごとに分割してリスト化します
内部の for ループ (for i in range(0, num, 2):) は、質問と回答のペアを処理します
2つごとにインデックスを進めることで、質問(q)とその直後の回答(a)を取得します
同じページから寄稿者情報(c)も browser.find_element(By.CLASS_NAME, “v2-selection-step-header__title”).text を使用して取得します
取得した質問、回答、寄稿者情報をそれぞれ question_list, answer_list, contribute_list に追加します
try-except ブロックは、処理中にエラーが発生した場合にプログラムが停止しないようにします
エラーが発生した場合は、そのES項目の処理をスキップして次に進みます
for url in tqdm(url_list):
print(url)
browser.get(url)
time.sleep(3)
elem = browser.find_element(By.CLASS_NAME, "v2-curriculum-item-body__content").text
elem = elem.split("\n")
num = len(elem)
for i in range(0, num, 2):
try:
q = elem[i]
a = elem[i+1]
c = browser.find_element(By.CLASS_NAME, "v2-selection-step-header__title").text
print(c)
print(q)
print(a)
print("")
question_list.append(q)
answer_list.append(a)
contribute_list.append(c)
except:
continue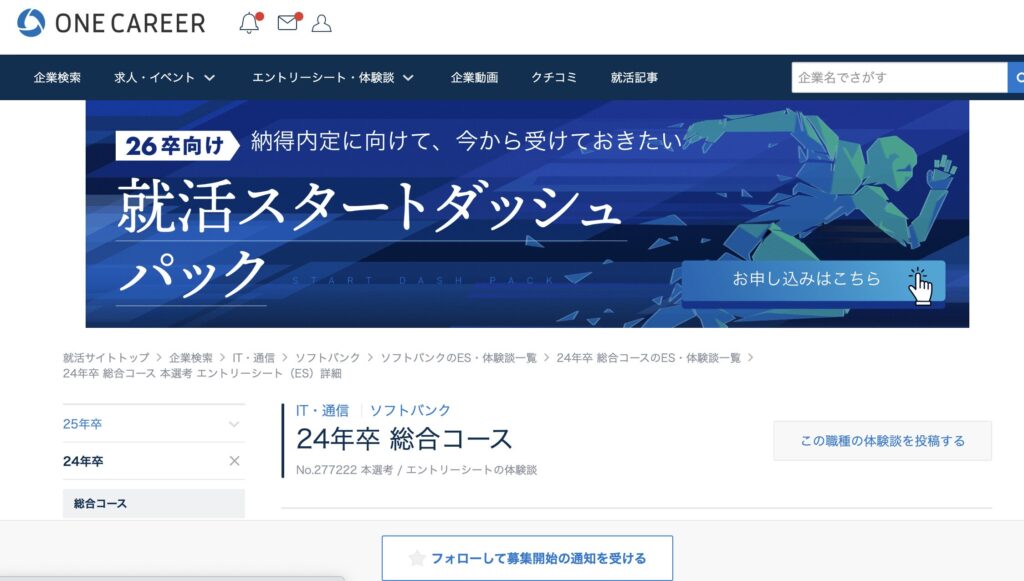
ここまでのコードを実行すると、自動で企業のES情報を収集することができます!
【STEP4】データを整理し、CSVファイルとして保存する

カテゴリ項目の定義とデータ準備
category_items は、DataFrameで使用されるカラム名(”問”、”答”、”属性”)を定義しています
length は、質問リスト(question_list)の長さを取得し、これが後でデータを処理する際のループの回数を決定します
data は、最終的なデータを格納するための空のリストを初期化します
category_items = ["問", "答", "属性"]
length = len(question_list)
data = []各質問、回答、寄稿者情報のデータ構造化
この for ループは、question_list、answer_list、contribute_list の各リストを通過し、それぞれの要素からデータを取得して detail というディクショナリに格納します
detail ディクショナリは、category_items に対応するキー(”問”、”答”、”属性”)に、それぞれのリストからの値を割り当てます
各イテレーションで、完成した detail ディクショナリ(datum としても指定されます)を data リストに追加します
for i in range(0, length):
detail = {}
detail[category_items[0]] = question_list[i]
detail[category_items[1]] = answer_list[i]
detail[category_items[2]] = contribute_list[i]
datum = detail
data.append(datum)Pandas DataFrameの作成とCSVへの保存
pd.DataFrame(data) を使用して、data リストからPandas DataFrameを作成します
DataFrameは、表形式のデータを操作するための便利な構造です
df.to_csv(company_name + “.csv”, index=False) は、DataFrameをCSVファイルとして保存します
ファイル名はユーザーが入力した会社名(company_name)に基づいており、.csv 拡張子が追加されます
index=False パラメータは、DataFrameのインデックスをCSVファイルに書き込まないように指定します
df = pd.DataFrame(data)
df.to_csv(company_name + ".csv", index=False)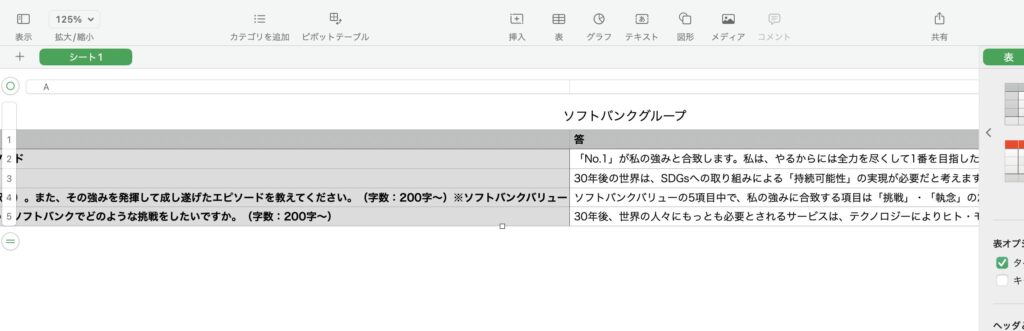
ここまでの、コードを実行すると、上の画像のように企業のES情報がまとまったcsvファイルが出力されます!
このプログラムで就活を少し有利に!
プログラミングでES対策も自動化することができる
このように、プログラムでESを整理して出力することができます
プログラミングって便利ですね
参照
僕のお友達のR.G.くんのコードを参考にさせていただきました

東京大学工学部B2。AIに興味があり、AI技術を活かした起業を目指して奮闘中。スマホアプリも作ってたりします。


コメント